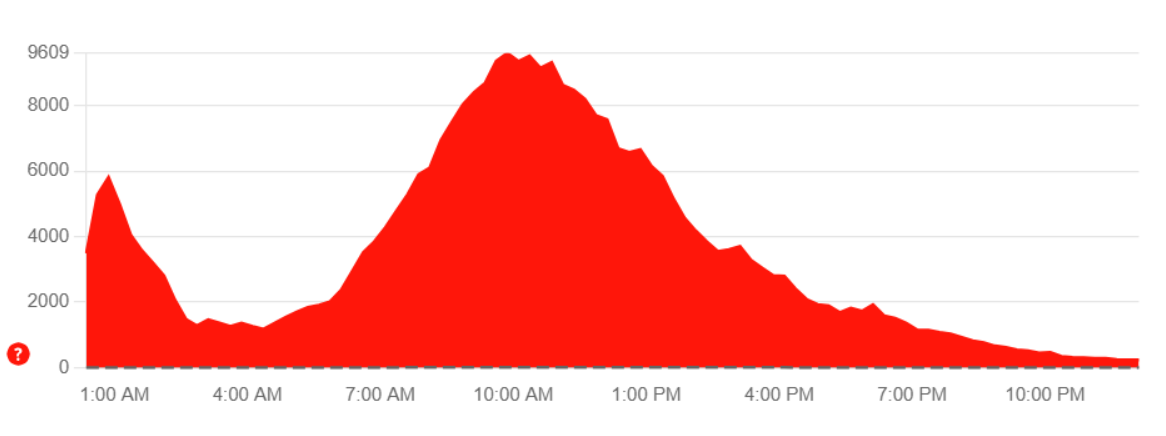
 AWS outage status on DownDetector showing widespread service disruptions
AWS outage status on DownDetector showing widespread service disruptions
At around 1 am today, I woke up because my phone kept buzzing from a series of alerts from work systems indicating various services were down. After some investigation, my team determined that it was an AWS outage, something I've dealt with before, but this one seemed to have a wider impact than usual.
What followed was a day that showed just how much we rely on cloud services.
Starting the Day
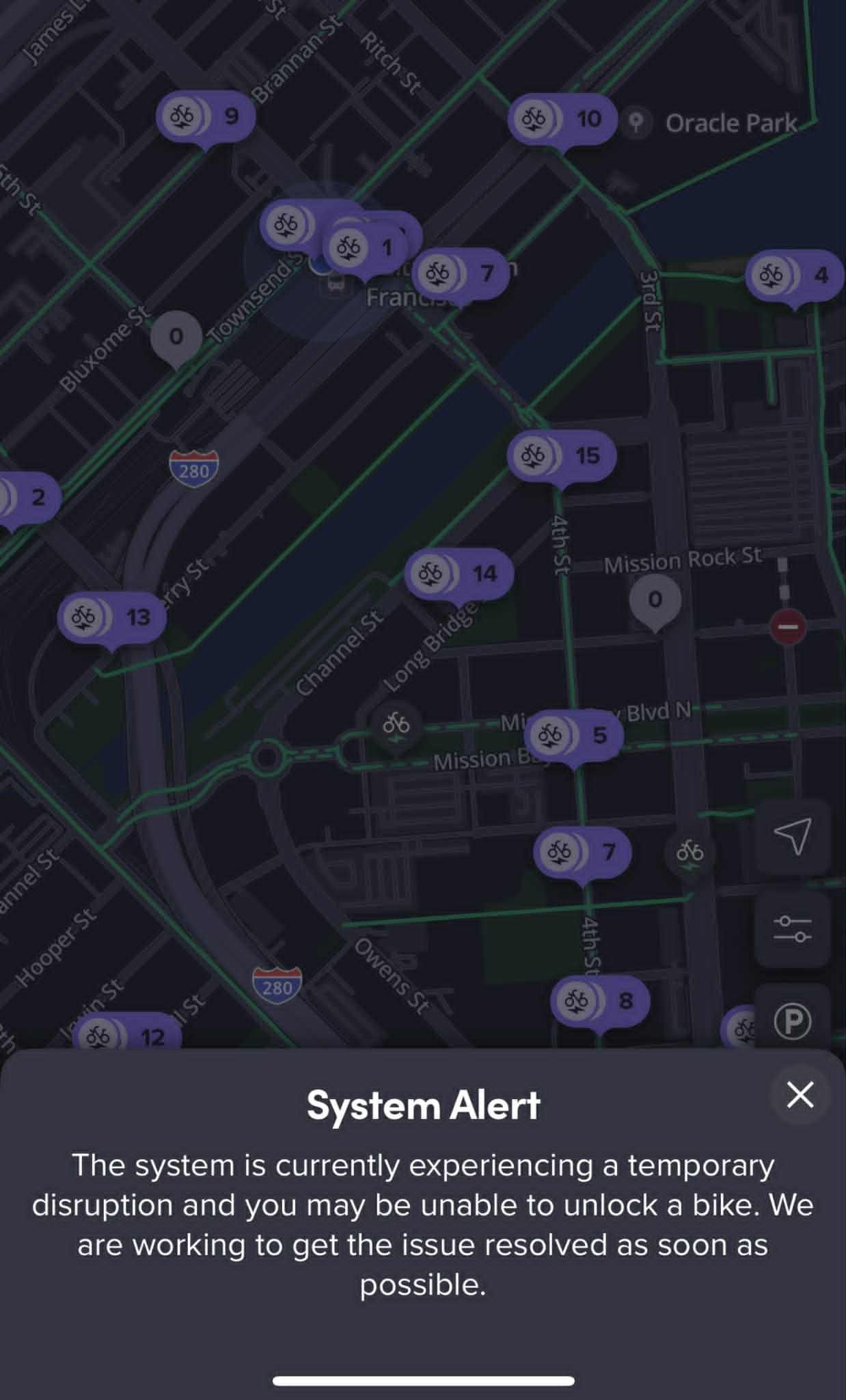
By the time I was ready to head to work, the AWS outage was already affecting services beyond just our internal systems. I usually use Lyft Baywheels to get from the Caltrain station to the office, but when I got to the 4th and King station, the bike-sharing system wasn't working.
 Lyft app showing service outage notification
Lyft app showing service outage notification
 The unusually full bike rack at 4th and King Caltrain Station - normally empty at this time of day
The unusually full bike rack at 4th and King Caltrain Station - normally empty at this time of day
What was weird was that the bike rack was completely full of bikes. Normally at this time of day, the rack would be nearly empty since commuters had already taken most of the bikes. The fact that it was full suggested the system had been down for a while, preventing people from both checking out and returning bikes. After a few attempts, I was able to get a bike and continue with my commute.
This experience showed something interesting about how we depend on cloud services. Even something as simple as bike sharing relies on cloud infrastructure for payment processing, user authentication, and real-time inventory management. When that infrastructure fails, the entire service becomes unusable, even though the physical bikes are still there and functional.
While I didn't experience it directly, the AWS outage had a big impact on social media platforms. Reddit and Snapchat were among the major services that went down, affecting millions of users worldwide. It's interesting how quickly we notice when these platforms are unavailable, even if we're not actively using them.
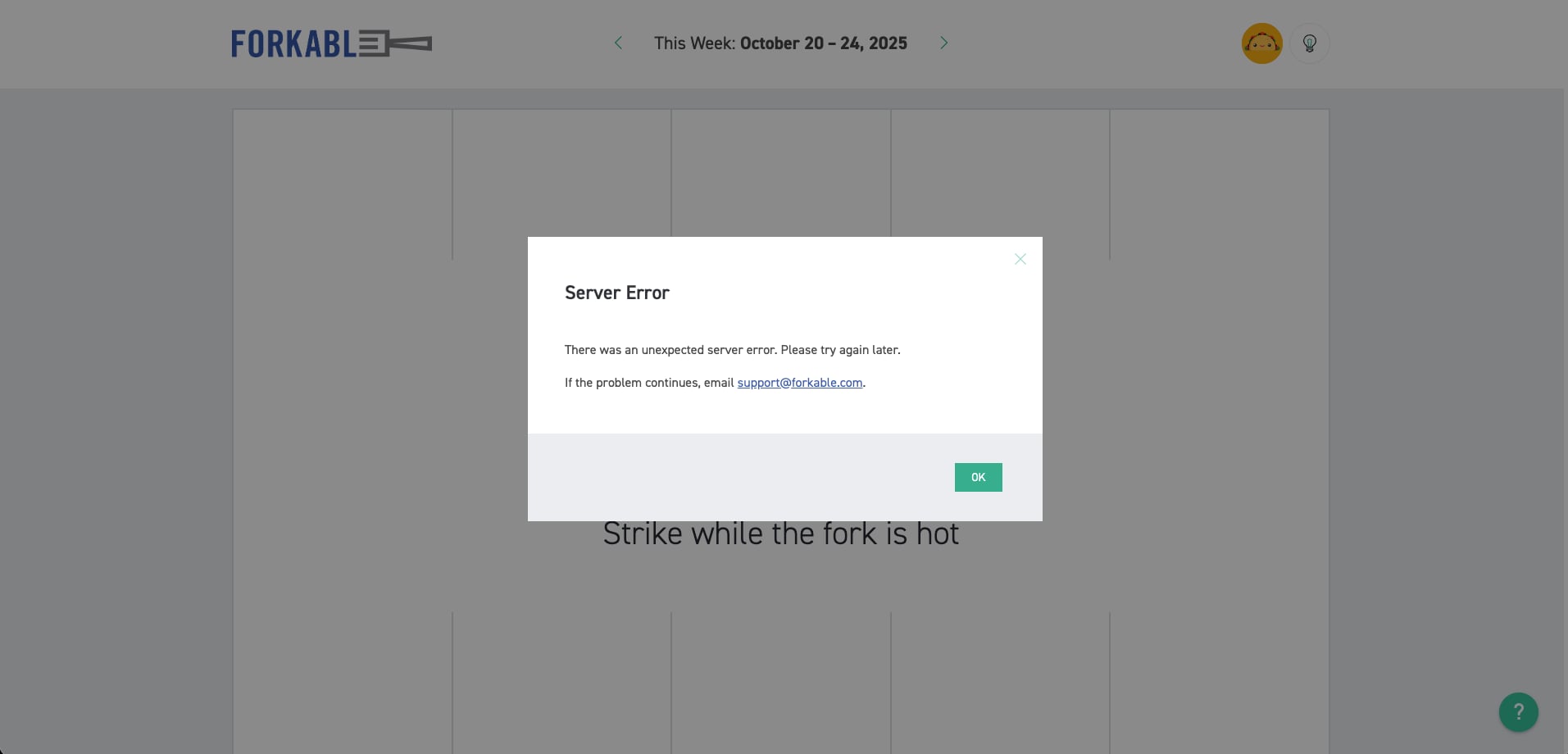
By lunchtime, the AWS outage had spread to Forkable, our company's food ordering service. This was frustrating because it's one of those services you don't think about until it's not working. The entire team was trying to place orders, but the system was completely down.
 Forkable service down due to AWS outage - eventually food was delivered once services were restored
Forkable service down due to AWS outage - eventually food was delivered once services were restored
What was interesting was that even though the system was down, the food eventually arrived. This suggests that the restaurant side of the operation was still working, but the ordering and payment processing systems were affected by the AWS outage. It's a good reminder that many modern services are actually a complex web of interconnected systems, and when one part fails, the entire chain can break down.
Eventually, the service was restored and our food was delivered, but it was a reminder of how dependent we've become on these digital intermediaries for even basic needs like food.
The Workday Chaos
Throughout the day, I got messages from various partner companies saying they were also dealing with AWS-related issues. This created a cascading effect where not only were our systems affected, but the systems of companies we depend on were also having problems.
Internally, many of our tools were down or having issues. I won't list the specific tools that were affected, as I don't want to reveal internal work details, but the outage had a big impact on our day-to-day operations.
What was challenging was the constant stream of alerts throughout the morning and early afternoon. Even though I knew the root cause was the AWS outage, I couldn't completely ignore the alerts because there was always the possibility of false positives or additional issues that needed attention. This created a state of constant vigilance that was both necessary and exhausting.
The Recovery Process
As the afternoon went on, it became clear that the AWS outage was starting to subside. Services were slowly coming back online, but the work wasn't over. The late afternoon was spent rerunning DAGs and making sure that all our systems were working properly now that the underlying infrastructure was stable.
This recovery process was almost as important as the initial response to the outage. Simply waiting for services to come back online isn't enough; you need to verify that everything is working correctly and that no data was lost or corrupted during the outage. This involves running tests, checking logs, and making sure that all dependent systems are functioning as expected.
Reflections
This AWS outage was a reminder of just how much we rely on cloud services in our daily lives. From the moment I woke up until late afternoon, AWS's infrastructure problems affected everything from my commute to my lunch plans to my work responsibilities.
What's striking is how these dependencies often go unnoticed until they fail. We take for granted that services like bike sharing, food delivery, and social media will always be available. But when the underlying infrastructure fails, we're reminded of just how fragile this interconnected system really is.
For engineers and technical professionals, outages like this serve as reminders of the importance of redundancy, monitoring, and disaster recovery planning. While we can't prevent cloud provider outages, we can design our systems to be more resilient and have better visibility into what's happening when things go wrong.
References
AWS Outage Status on DownDetector:
https://downdetector.com/status/aws-amazon-web-services/